Awesome Twitter Word Clouds in R

Twitter Word Clouds in R
We have officially kicked off summer of 2018! Y'all know what that means right? SUMMER OF DATA SCIENCE!!! Imagine it now, you could be soaking up the rays while harnessing your inner data science skills ALL. SUMMER. LONG!!
Summer of data science (aka #SoDS18 on twitter) is a community created by Data Science Renee to support and promote learning new data science skills in a collaborative environment. The community releases a list of books to collectively tackle during the program. To participate; you pick a book, work through it and collaborate in the social channels of your choice (slack, twitter etc).
For my goals, I decided to work through the book Tidy Text Mining with R by Julia Silge and David Robinson I chose to tap into Twitter data for my text analysis using the rtweets package. Inspired by some of the word clouds in the Tidy Text book, I decided to plot the data in fancy word clouds using
Set Up R
In terms of setting up the R working environment, we have a couple of options open to us. We can use something like R Studio for a local analytics on our personal computer. Or we can use a free, hosted, multi-language collaboration environment like Watson Studio. If you'd like to get started with R in IBM Watson Studio, please have a look at the tutorial I wrote.
1) Install and Load the Libraries
The first thing we need to do is install and load all required packages for our summertime fun work with R. These are all of the install.packages() and library() commands below. Note that some packages can be installed directly via CRAN and some need to be installed from github via the devtools package. I wrote a blog on navigating various R package install issues here.
install.packages("rtweet")
install.packages("tidytext")
install.packages("dplyr")
install.packages("stringr")
require(devtools)
install_github("lchiffon/wordcloud2")
library(tidytext)
library(dplyr)
library(stringr)
library(rtweet)
library(wordcloud2)2) Twitter API Authorization
Before we get rolling, we need some data. Let's tap into twitter using the rtweets package. rtweet is an excellent package for pulling twitter data. However, first you need to be authorized to pull from the twitter API. To get my API credentials, I followed the processes documented in rtweet reference article and the github readme page. Following these steps, the process was pretty seamless. I would only add that I had to uncheck "Enable Callback Locking" to establish my token in step 2.
3) Establish your token
Execute the following code to to establish your token. As per the rtweet reference article, the create_token() function automatically saves your token as an environment variable for future use.
create_token(
app = "PLACE YOUR APP NAME HERE",
consumer_key = "PLACE YOUR CONSUMER KEY HERE",
consumer_secret = "PLACE YOUR CONSUMER SECRET HERE")4) Gather Tweets via rtweet search_tweets function
Use the search_tweets() function to grab 2000 tweets with the hashtag of your choice. I chose to look into #HandmaidsTale because the show is AMAZING. We will then look at the data collected from the tweets via the head() and dim() commands. We will then use the unnest() command to transform the data to have only one word per row. Next, we remove common words such as "the", "it" etc via the stop_words data set. Finally, we will filter out a custom set of words of our choice.
#Grab tweets - note: reduce to 1000 if it's slow
hmt <- search_tweets(
"#HandmaidsTale", n = 2000, include_rts = FALSE
)
#Look at tweets
head(hmt)
dim(hmt)
hmt$text
#Unnest the words - code via Tidy Text
hmtTable <- hmt %>%
unnest_tokens(word, text)
#remove stop words - aka typically very common words such as "the", "of" etc
data(stop_words)
hmtTable <- hmtTable %>%
anti_join(stop_words)
#do a word count
hmtTable <- hmtTable %>%
count(word, sort = TRUE)
hmtTable
#Remove other nonsense words
hmtTable <-hmtTable %>%
filter(!word %in% c('t.co', 'https', 'handmaidstale', "handmaid's", 'season', 'episode', 'de', 'handmaidsonhulu', 'tvtime',
'watched', 'watching', 'watch', 'la', "it's", 'el', 'en', 'tv',
'je', 'ep', 'week', 'amp'))
5) Create a Word Cloud with the wordcloud2 package
Use the wordcloud2() function out of the box to create a wordcloud on the #HandmaidsTale tweets.
wordcloud2(hmtTable, size=0.7)
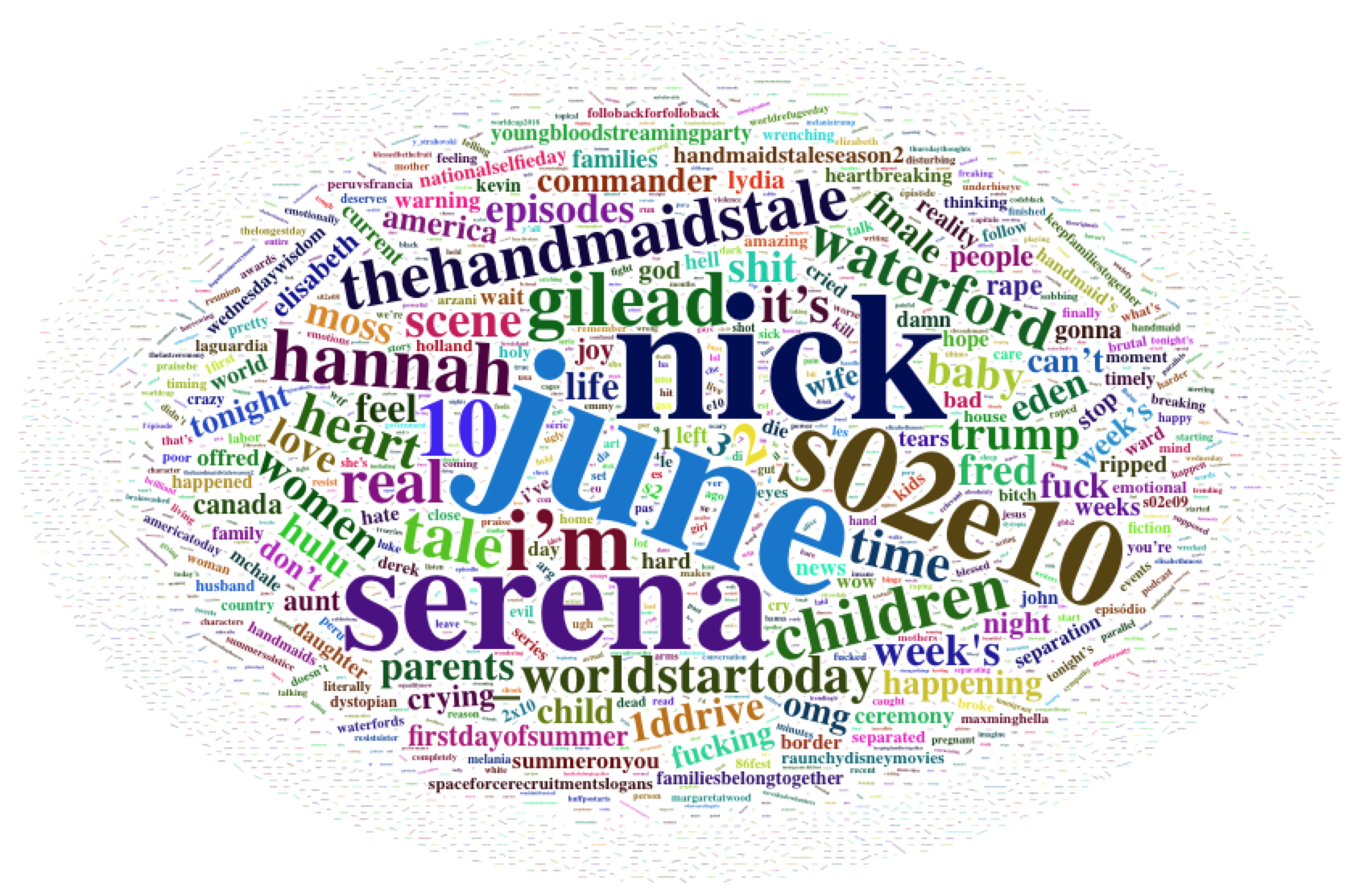
6) Create a Better Word Cloud
That word cloud was nice, but I think we can do better! We need a color palette that suits the show and we would like a more suitable shape. To do this we create a list of hex codes for our redPalette. We then use the download.file() function to download some symbols from my github. Note that you can also very easily create the word cloud shape by referencing local files. Finally we create the word cloud via the wordcloud2() function and we set the shape with the figPath attribute.
#Create Palette
redPalette <- c("#5c1010", "#6f0000", "#560d0d", "#c30101", "#940000")
redPalette
#Download images for plotting
url = "https://raw.githubusercontent.com/lgellis/MiscTutorial/master/twitter_wordcloud/handmaiden.jpeg"
handmaiden <- "handmaiden.jpg"
download.file(url, handmaiden) # download file
url = "https://raw.githubusercontent.com/lgellis/MiscTutorial/master/twitter_wordcloud/resistance.jpeg"
resistance <- "resistance.jpeg"
download.file(url, resistance) # download file
#plots
wordcloud2(hmtTable, size=1.6, figPath = handmaiden, color=rep_len( redPalette, nrow(hmtTable) ) )
wordcloud2(hmtTable, size=1.6, figPath = resistance, color=rep_len( redPalette, nrow(hmtTable) ) )
wordcloud2(hmtTable, size=1.6, figPath = resistance, color="#B20000")
7) Marvel at your amazing word cloud
Yes, you have done it! You've made a pretty sweet word cloud about an epic tv show. Word clouds with custom symbols are a great way to make an immediate impact on your audience.


8) Go wild on word clouds
Now that you've learned this trick, it's time to unleash your new #SoDS18 powers on the subjects of your choice! In keeping with the TV theme, I can't forget Westworld. Below are a few more Westworld visualizations I created following similar steps to above. All code is available in my github repo.


Thank You
Thanks for reading along while we explored twitter data, the beginnings of text analysis and cool word clouds. Please share your thoughts and creations with me on twitter.
Note that the full code is available on my github repo. If you have trouble downloading the file from github, go to the main page of the repo and select "Clone or Download" and then "Download Zip".